Papers: BinRec: Dynamic Binary Lifting and Recompilation
- A summary of the paper BinRec: Dynamic Binary Lifting and Recompilation presented at EuroSys'20.
BinRec is novel tool for binary lifting and recompilation which uses dynamic techniques to generate new binaries, in contrast to existing biniary recompilers like McSema and Rev.Ng which use static analysis and heuristic techniques to facilitate recompilation. BinRec employs dynamic analysis to lift binary code to LLVM IR and subsequently lowers it back to machine code, producing a “recovered” binary.
Binary Rewriting
Binary rewriting is the process of taking compiled binaries, which are usually release builds with stripped symbols and no debug information and modifying the code contained in them to enable more functionality. Rewriting has applications in post-installation program hardening, deobfuscation, and reoptimization. Compiled assembly code is not very expressive and difficult to rewrite, thus the concept of binary lifting is used for raising machine code to high-level intermediate representations such as LLVM bitcode, this allows powerful compiler-level analysis on binaries with no available source code.
Static Analysis
Existing binary lifting techniques use static disassembly (McSema uses IDA Pro to generate its Control-Flow Graphs) to generate control flow graphs for binaries, which is unable to accurately represent code-flow, code pointers, data, and instructions. Heuristics have been used to circumvent the limitations of static disassembly, but it limits rewriting to binaries within certain assumptions.
Dynamic Analysis
In contrast to static rewriting techniques, dynamic techniques use dynamic binary translation tools (Pin, DynamRIO, etc) to analyze binary control-flow paths at runtime. DBT tools are also limited in terms of working at the level of machine code, and code is rewritten at run time and thus needs to be rewritten at every execution, which severely degrades performance.
BinRec employs dynamic analysis to lift binary code to LLVM IR and subsequently lowers it back to machine code, producing a “recovered” binary. Dynamic analysis presents a problem that only specific code-paths can be covered in the concrete executions, a control flow miss. BinRec uses customizable control-flow handlers and incremental lifting allowing unknown edges and retrofitting binary with the newly found code path. The authors applied two security transformations available in LLVM- SafeStack, and AddressSanitizer to the lifted LLVM IR and produced a recovered binary successfully.
Limitations in Binary Lifting
Some key considerations for binary lifting tools, and why static analysis is insufficient for binary lifting.
- C1. Code vs Data, and Reference Ambiguity
Appropriate labels are present in code to identify code from data and reference from constants, these labels are not provided with stock compilers. A dynamic tool, in this case, can accurately assign labels by observing how the CPU interprets the values it reads from the memory.
- C2. Indirect Control Flow
Indirect Control Flow Transfers (iCFTs) transfer control to one or more target locations based on their execution context. In C, this could be function pointers, and even more prevalent in C++ code via virtual functions. Resolving iCFT function calls and returns statically is difficult, One technique uses lookup-tables to select the correct branch during runtime, a hybrid static-dynamic approach. Dynamic tracing can reliably identify code jumps by following the code jumps in the CPU by directly recording the target address to jump to.
- C3. External Entry Points
Dynamic Linking presents hurdles in analyzing binaries statically as rewriting external binaries is infeasible and requires static linking, which incurs large overhead. Thus, statical analysis is only able to get a partial view of the code. Various solutions like run-time lookup tables, special case handlers have been implemented in the past costing large overhead. Dynamic tracing can capture these entry points by recording control flow transfers going in and out of target code space enabling performant granular control and modification at these points.
- C4. Ill-formed code
Anti-Disassembly, Anti-Debugging techniques, heavy compiler optimizations, manually written assembly optimizations can generate ill-formed instruction constructs. Overlapping instructions, inlined data, jump tables, switch cases, overlapping basic blocks, multi-entry functions, and tail calls prevent effective static analysis. Dynamic tracing bypasses ill-formed code as it directly observes the instructions executed by the CPU.
- C5. Obfuscation
Obfuscation is explicitly done to prevent analysis, techniques like virtualization obfuscators use bytecode to obfuscate code and interpret them via an embedded virtual machine, static analysis of these obfuscated sections show no behavior information about the code. Other techniques include opaque predicates, control-flow flattening, and aliasing. Dynamic lifting can revert all of these obfuscations to some extent, capturing virtual machine-translated code, remove dead code, and spurious aliases.
BinRec Design
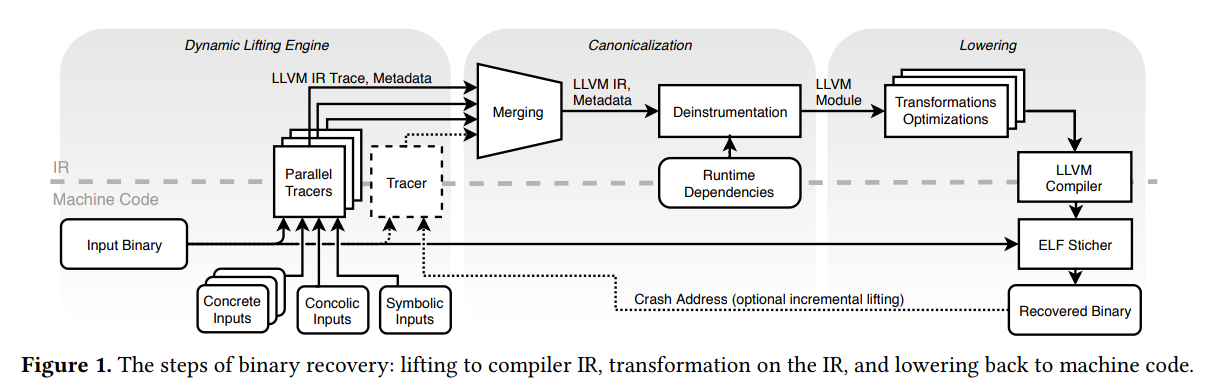
The design goals of BinRec are to focus on Coverage and Scalability. Coverage is driving execution through all desirable code-paths as required by the user (partial, most frequent, or only trusted input paths). Scalability is the ability to prevent code path explosion in a single trace and parallelise code-path tracing into smaller manageable chunks.
BinRec is separated into the Dynamic Lifting Engine, the Canonicalization process and the Lowering process (ending with a compiler compiling the recovered LLVM IR bitcode and stitching the new recovered binary together with the original binary).
Dynamic Lfting Engine
- The Execution Driver allows controlling input to the executing binary using various methods during analysis. This can include a user-supplied corpus of cmd-line/stdin input, inputs to enable concolic execution which aims to get complete code-coverage on the analyzed binary and fuzzer-generated inputs. Both explicit (cmd line, stdin) and implicit inputs (timers, random number generators, interrupts, network packets, address layout) needs equal consideration for high coverage of code.
- The Dynamic Data Recording module records every execution path, this recording contains instructions that were executed, where function boundaries are, and the observed targets of each branch instructions. This recorded data is accurate on all the paths tested during execution, but remains unsure on paths not covered in the analysis. Limitations C4 (Ill-formed code) and some parts of C5 (Obfuscation) are addressed by this module at the expense of a slower front-end.
Canonicalization
- BinRec can merge N traces in parallel (which could be driven by fuzzing, concolic execution, or chosen input), and then a single LLVM IR module can be created from the N LLVM IR modules using metadata collected after lifting. Merging depends on the correlation of code from multiple traces. This is a path-insensitive procedure, the resulting CFG resembles the original program’s CFG but lacks nodes that were not executed while lifting.
- BinRec uses an emulation-based dynamic lifting engine, IR generated from such an engine is heavily instrumented. Dependencies on the run-time environment are removed from lifted code and merges all captured code into a single LLVM module. The lifted IR of a recovered program has an abstract representation of the memory model in the original binary.
- A program with two stacks and register sets is generated, a native stack, and an emulated stack and register set containing data of the original binary. Generated code interacts with the emulated environment to reproduce functionality of original program.
Control-Flow Canonicalization
- The lifting front-end produces executed basic-blocks, and a list of control-flow edges. This is used to emit control flow transfers to a precise list of allowed targets. The address that will be used to jump in the original code will be recorded, this is used as a key in the recovered binary to determine the address to jump to. Indirect Control-Flow Optimization can be achieved using this list of allowed targets where the seperate native stacks can govern over which address are allowed to be jumped to in the emulated state and which are not.
- BinRec supports calling external libraries calls by marshalling the emulated programming state into a concrete state which can match the ABI of the linked libraries. Upon return, the emulated state is reloaded into the emulated state. State includes full register set and the stack pointer.
- BinRec records records call targets where the caller is outside the analysis region of the original binary (i.e in a callback function). The instruction pointer value is recorded when the called back code exits to library code via call or ret. Entry stubs and exit stubs for external code transitions are added to the recovered binaries. This is a solution to limitation C3.
- Data Canonicalization
- Accurate lifting of data structures from binaries is difficult as interleaving of code and data is allowed. BinRec includes data and sections from the client binaries as global variables in the IR.
Lowering
- An unmodified LLVM compiler is used to generate a temporary ELF from recovered IR, then the lowering toolchain stitches together ELF sections from the temporary binary and the original binary into one combined binary, binary patching happens to insert code trampolines (voluntary interrupts) to support external callbacks, and update dynamic linking structures.
- All dynamic data and code references into canonical LLVM IR, and then lower this IR using LLVM’s code generation infrastructure. Static references and dynamic addresses of indirect loads are both collected, which can thus be redirected to external symbols enabling Dynamic Linking to work as intended on lifted Data Structures.
Control Flow Miss Handling
Recovered binaries may encounter unrecovered paths during testing or after deployment due to coverage limitations. A control flow miss handler is invoked whenever an unrecovered path is found. There are various handlers available:
- Log handler - logs the instruction pointer value that is missing from the recovered binary and aborts execution.
- Fallback handler - diverts execution from recovered code into the original code of the input binary. The emulated CPU state is to be converted for the original binary to use. This prevents unexpected termination.
- Incremental lifting - feeds back the logged missing instruction pointers into the dynamic lifting engine, where a new trace is captured controlling the control-flow edge, merging it with the other traces. In this manner, recovered binary can be continuously updated.
The recovered program uses the log or fallback handler, the lifting engine uses incremental lifting. New code cann be directly lifted without the need to reproduce input that triggers miss during lifting. Once all code paths have been incrementally lifted, the miss handler can be completely removed.
Implementation
Targets 32-bit x86 binaries for Linux. Dynamic Lifting Engine uses S2E for symbolic execution of a single process inside QEMU, code is translated to LLVM IR in order to be symbolically executed by the KLEE symbolic executor. This prototype supports Parallel Tracing where multiple traces through the same binary are lifted in parallel, it is also possible to lift different binaries in parallel. The dynamic trace is stored on the disk can be copied, shared, and reused. Deinstrumentation of S2E instrumented is performed as an optimization along with other optimizations. An important Stack Unwinding Optimization is including for switching between the native and emulated stack.
Comparison and Performance
BinRec was evaluated using the SPEC CPU2006 benchmark suite binaries for lifting and recompilation, focusing on run time, code coverage and lifting speed.
In contrast to BinRec, McSema and Rev.Ng use static analysis for analyzing binaries and recovering control-flow graphs. In the authors' test’s, McSema encountered various errors and couldn’t properly recover the binaries under test. Rev.Ng was even worse with only being able to recover only a few binaries (at the O0 optimization level).
- Performance
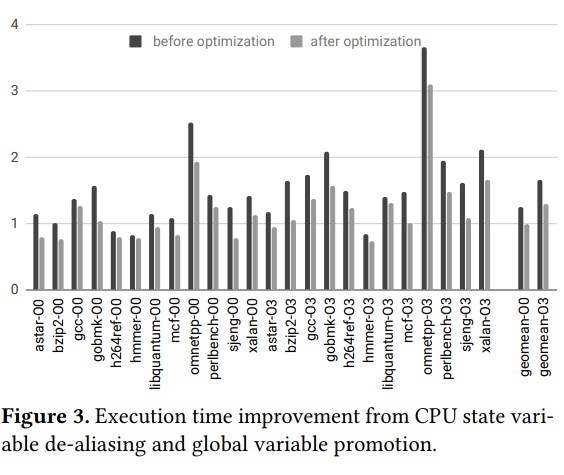
- Post-release optimization using BinRec improved the performance of benchmarks in at least 6 cases. A penalty was incurred due to the emulation of floating-point instructions using integer instructions. In one case, hmmer turned out to be faster (0.62x) on re-optimization compared to the original binary (0.85x). On average, BinRec unoptimized and optimized binaries run-time resulted to be 0.98x and 1.29x.
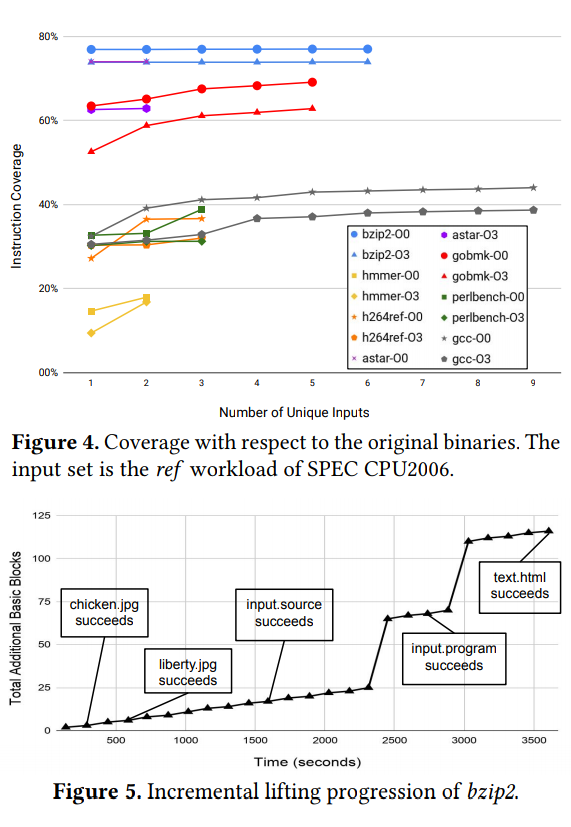
- Code Coverage
- The rate of coverage depends significantly on the binaries themselves. Some binaries use mostly the same code paths always while others see a steady increase in code coverage at each added input. Users could also aim to increase coverage or to make it low, limiting the attack surface for attackers. Incremental lifting was especially instrumental in increased code coverage and decreased lifting time.
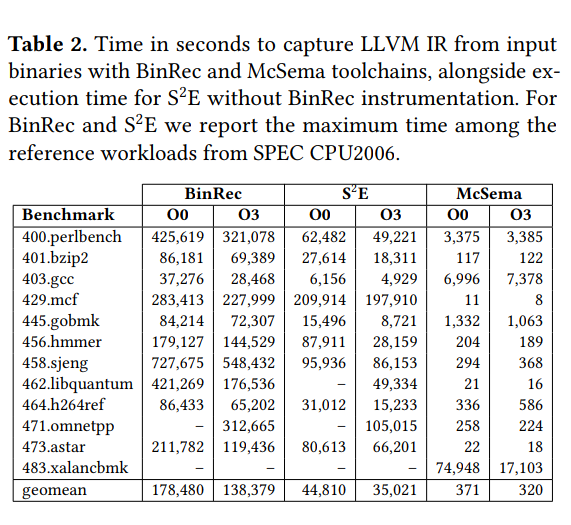
- Lifting Time
- Lifting Time depends on the execution time of its input programs. As traces for the binaries are generated, they can be reused, thus optimizing the lift time. Compared to static analysis like McSema, Lifting Time is variable whereas in McSema it is fixed to the time it takes to perform static analysis on the binary.
- Lifting time is also limited by the performance of the S2E tracing frontend, replacing it with Pin can improve performance. Replacing QEMU for KVM-QEMU or hardware control-flow tracing can increase performance.
Applications
BinRec’s goal is to let existing analysis utilities like readelf and LD_PRELOAD be compatible with recovered binaries, they presented various applications possible with recovered IR.
- Control-Flow Hijacking Mitigation
- Control-Flow Integrity is provided in the recovered binary as the code paths generated by the traces are emulated inside the binary and thus the code-paths cannot have indirect branches in case of a vulnerable application. Context-Insensitive Control Flow Integrity on Forward & Backward Edges. An attacker overwriting a return address which updates the emulated RIP will not be jumped to as it is not an allowed target in the native code. Hijacking via writing code pointers is mitigated.
- Virtualization Deobfuscation
- Process based VM obfuscation can be deobfuscated by following the executed code paths in the original binary and producing a recovered binary.
- Address Sanitization (ASan)
- ASan instrumentation is a LLVM instrumentation which identifies and registers memory allocation, and insert checks for memory accesses.
- SafeStack
- It is a compiler-based transformation that separates sensitive data like return data from data buffers into separate stacks. By default, BinRec generates two stacks, one native and emulated, the native stack contains sensitive data like return addresses. The emulated stack contains data of original binary, at an ASLR-randomized location.
Limitations
The prototype can only handle single threading x86 ELF binaries. Supporting PE requires implementing binary stitching for the new format and thread-safe data structures to collect traces from each individual thread. Self-modifying code is also not supported in the prototype.
Conclusion
BinRec lifts a program to compiler-level intermediate code for ease of analysis, while ensuring that it can still compile to executable code. It can seamlessly handle indirect control flow transfers, handwritten assembly and obfuscations. BinRec solves the coverage problem using incremental trace recovery and trace merging. Various powerful applications are possible using BinRec: recovering semantics of virtualization-obfuscation, binary hardenening, and applying compiler-level optimizations and hardening transformations to stripped binaries.